


What's Web Scraping?
What's Web Scraping?
Getting info from websites automatically, with code

This is a guest post from Leonardo at ScraperAPI. If you’re looking for an enterprise-level data collection tool without the big price tag, check them out.
The TL;DR
Web scraping is a technique to automatically collect data from websites (e.g., text, images, product prices, stock data, etc.) through code.
Web Scraping comes down to four steps: picking a URL, accessing the data programmatically (through code), extracting the needed information, and storing the data for later use or analysis
Many websites use anti-scraping mechanisms to block bots from accessing their data, like organizing and naming website elements in confusing ways
Most engineers use open source libraries to scrape websites, but simpler beginner-friendly tools exist to help non-technical folks gather the data they need
Web scraping plays a role in many of the tools we use on a daily basis. From Google getting the information they need to make their search engine work, to AI companies (e.g. ChatGPT) collecting web data to train their models.
Understanding Web Scraping
Web scraping is the process of collecting publicly available web data with code. The execution is done programmatically through scripts and/or tools (web scrapers), automating the entire data collection process.
Basically, using web scraping, we can take a website like this:
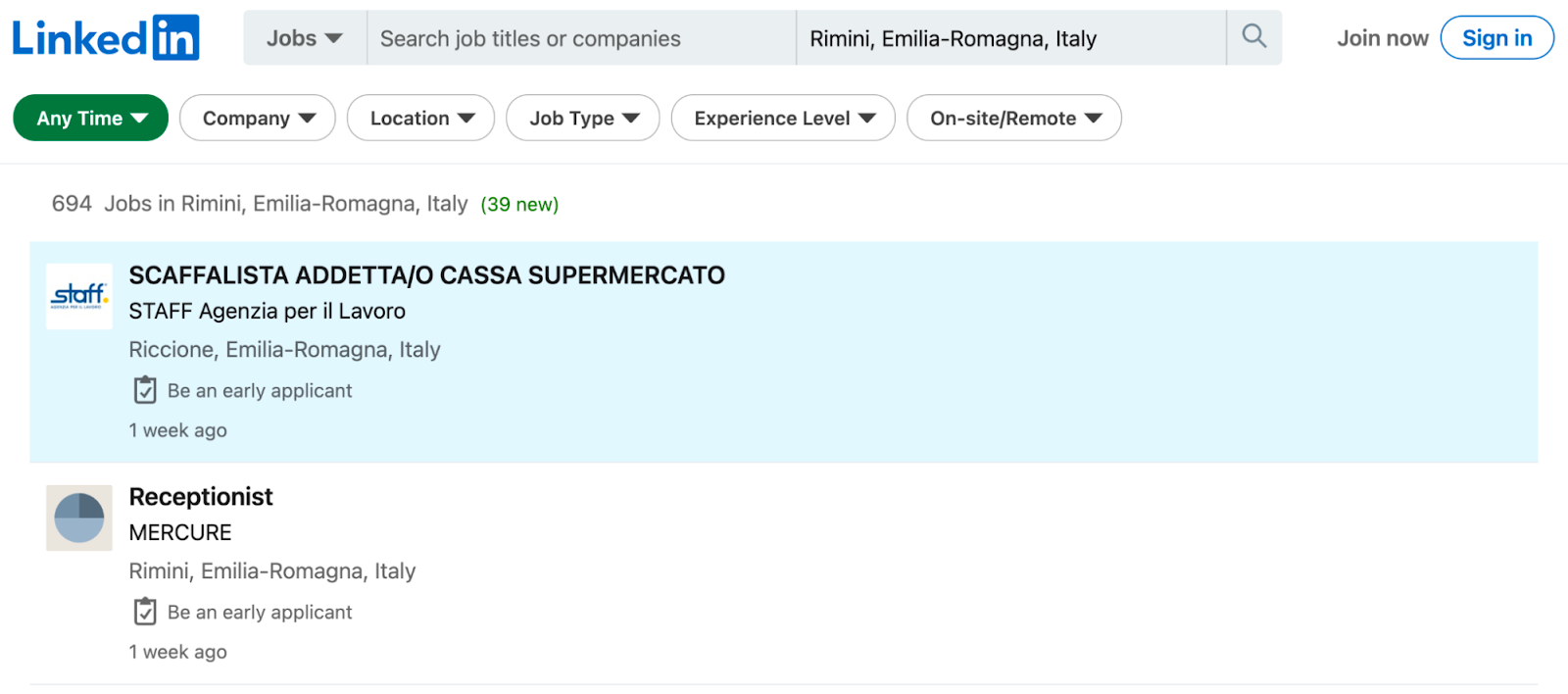
And store all its data into a database or file like this:
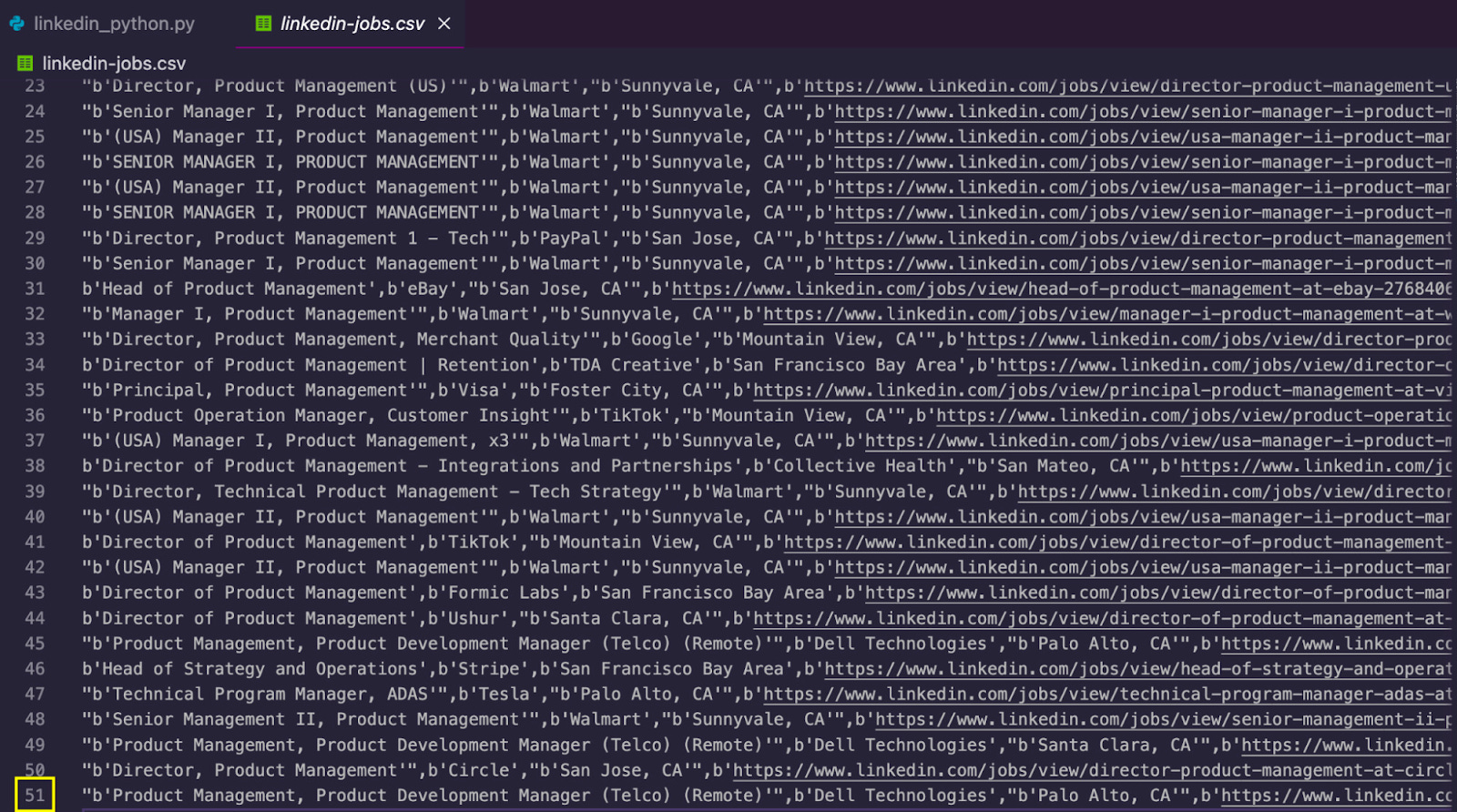
Under the hood, you can imagine a sort of bot whose task is to visit a website, find the information you’re looking for, and then bring it back to you. It’s like training your dog (your computer) to bring you stuff… but from the web.
The principle underlying all of this is pretty simple: a website is just data, organized in a nice visually appealing way. When you’re browsing around the web, you want those LinkedIn jobs to be formatted and organized with colors, buttons, and all that. But sometimes you just want the data, and that’s when you scrape.
To make things more concrete, let’s get into how a web scraper actually gets built.
Web Scraper Example
Here’s an example of a very simple web scraper in Python. We’re trying to scrape some quotes from here. Here’s what the page looks like:
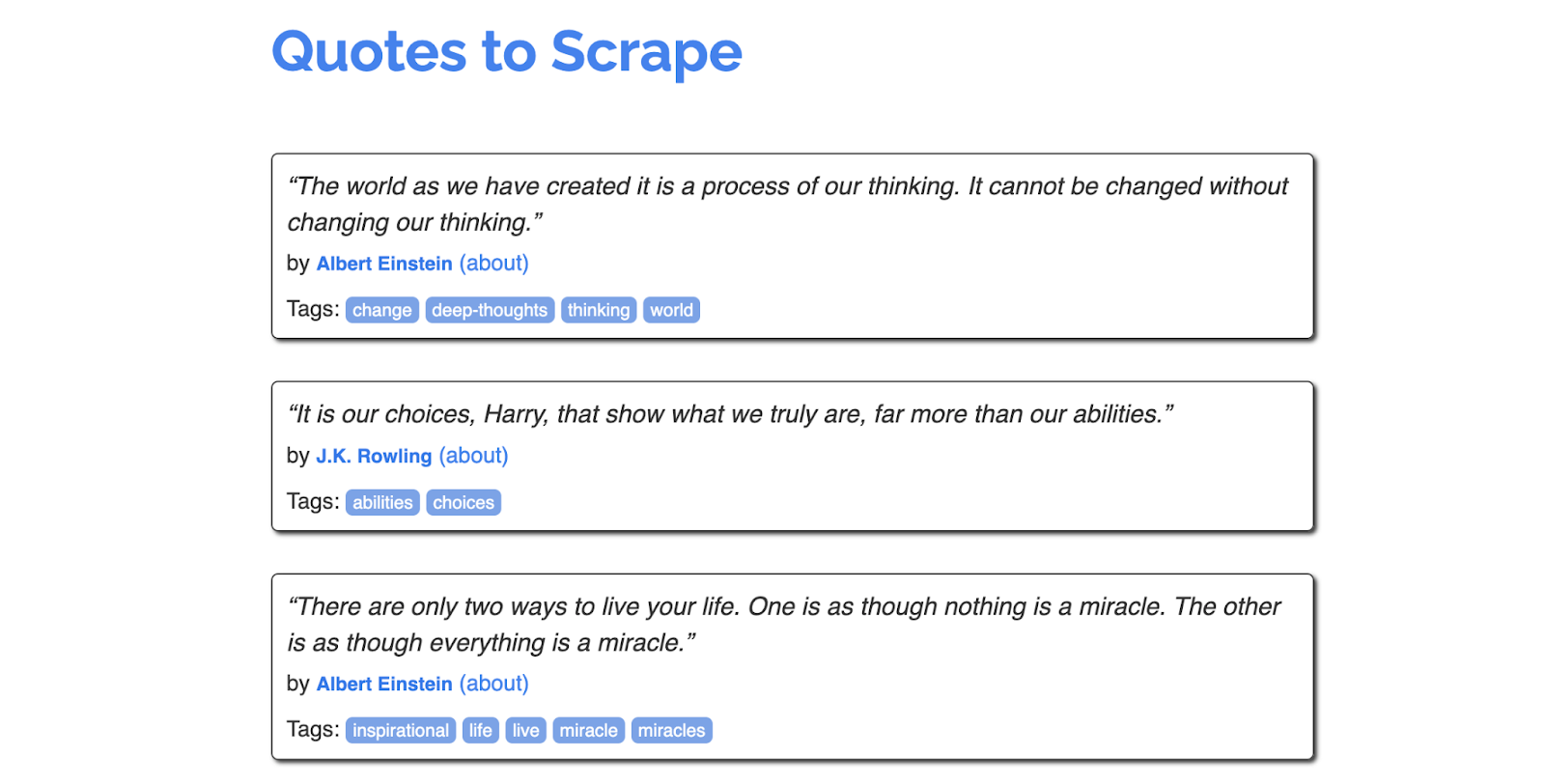
And here’s what the scraper might look like:
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
all_quotes = soup.find_all('div', class_='quote')
for quote in all_quotes:
quote_text = quote.find('span', class_='text').text
print(quote_text)Don’t panic! Here’s a quick breakdown (line by line) of what’s happening in this code:
This script is written in Python.
Inside the variable
urlwe’ve defined the page we want our scraper to visit.response = requests.get(url)is the way we send our request to download the HTML file. Basically, telling the tool requests toget()us the HTML of the page defined inurl. It’s the programming equivalent of visiting the website in your browser.BeautifulSoup (yes, real name) is a popular Python package for web scraping.
BeautifulSoup(response.content, 'html.parser')takes the HTML and decodes it into human readable words.Next, we run through all of the quotes on the page, extract their information, and print them out.

And there’s a web scraper! If you were using this at work, you’d probably store these quotes in a database or a file instead of just printing them out in your command line. But it’s a start! If you’re interested in building your own, check out this step-by-step guide.
How Web Scraping works under the hood
(feel free to skip this section if you’re less interested in the technical side of things)
The code above was pretty simple – hopefully you’ve gotten the gist that web scraping isn’t the most technically demanding thing a software engineer does on a daily basis. What makes it difficult is the logic of figuring out how to download and organize the information on the site itself. So let’s walk through what that process looks like:
The entire process begins by providing the web scraper with a URL or list of URLs to visit.
The scraper will then send an HTTP request to the server where the URL is hosted to download the HTML file of the page.
If the scraper gets access to the raw HTML, it’ll parse, or break down and interpret, the file. It will turn it into a parse tree (basically a hierarchically organized representation of the HTML) so we can navigate it and pick the elements.

Targeting the specific HTML tags or CSS selectors specified by you, the scraper will extract the defined elements or data points you’re interested in.
Note: The information we are extracting must be publicly available. Extracting sensitive data or information behind pay or login walls is usually illegal, as these are direct violations of terms of service and privacy laws.
After returning the elements, it will format all this information according to your specifications (text, JSON, CSV, or any other format).
🚨 Confusion Alert 🚨
On a fundamental level, understanding how websites are structured is the key ingredient for your web scraping success. The rest is just choosing the right tools (and having some patience and creativity to decipher the best way to access the data).
🚨 Confusion Alert 🚨
Every website is like a unique puzzle. After all, developers build websites in many different ways. Still, the basic web scraping process is consistent across all projects: deciding the target pages > accessing the data > extracting the elements based on specific criteria > outputting the information.
Anti-Scraping Mechanisms and Other Challenges
Just because a website shows data publicly doesn’t mean they want you to scrape it. This is a reality that you’ll have to face.
Because so many people abused web scrapers in the early days, hurting sites by overwhelming their servers and taking resources away from their real visitors, today it is standard practice for established (and an increasing number of not well-known) websites to implement anti-scraping mechanisms. These techniques aim to identify and block bots, i.e. you.
As a rule of thumb, you’ll want to work with websites respectfully and avoid hurting them with your scripts.
These anti-scraping mechanisms are more complex and tougher to bypass the bigger and more popular the website is. For example, scraping quotes.toscrape.com doesn’t represent any challenge, while if you try to send just a couple of requests to Amazon, Google, or LinkedIn, you’ll soon get blocked.
That’s why using web scraping solutions like ScraperAPI is critical to collect data at scale. These tools allow you to bypass IP blocks, CAPTCHA tests, and any other anti-scraping mechanism thrown at you while also automating most of the technical stuff, letting you focus on data instead of coding.
What did you think of this post?
Ideas for me to write about? Reply to this email, or if you’re reading this on the web, email me here.
maybe one of the best guest posts i've seen on here. great job leonardo.
v.. nce