


How does a feature get made?
How does a feature get made?
Walking practically through how an engineer builds something

The TL;DR
Here at Technically Inc., we pride ourselves on explaining each part of the software stack in an accessible and friendly way. But every now and then, it’s important to think about how these pieces fit together, and how engineers use them. This week, we’re going to walk through exactly what happens when an engineer builds something new, from ideation to new code making its way to users.
If you’re:
At a tech company, wondering why your developers told you a small feature would take 3 months to build
A financier trying to understand what CI/CD is and where it fits into the stack
Generally a chill, cool person
This post is for you!
I like to split the building process into 4 steps:
Decide what to work on
Build it locally
Get code ready for production
Get code into production
To make the story easier to follow, let’s imagine that you’re an engineer at Substack.
Decide what to work on
At tech companies, software engineering is almost always considered the most scarce resource at the company. Engineers (especially good ones) are difficult to hire, highly paid, and have a straightforward work product – so naturally, what companies have them working on is a source of much thought and deliberation.
This is second nature if you’ve worked at a tech company, but if you haven’t it’s worth stressing – deciding what engineers build and fix is one of the core decision making processes at startups and large companies alike. If a company has a product manager, a big part of that job is building a roadmap of what we should build and why we should build this as opposed to anything else. In other cases, the engineers themselves have autonomy to decide what they work on.
You can fit the types of work that engineers do into 4 buckets:
Bug fixes – fixing things that don’t work or look right in the product. The more complex your company’s product is, the more common this is and the more time it takes.
Small features – small, straightforward additions or changes to the product. At Substack, this might look like adding a new type of filter to the subscribers view.
Big features – self contained, meaningful new product capabilities. At Substack, this might look like adding functionality for adding referrals to your newsletter.
Refactoring – going back to old code and cleaning it up, making it more efficient, easier to read, and more stable.
Bug fixes are usually the quickest, and the line between small features and big features can blur. There’s also code and process around infrastructure (DevOps) that we’ll skip here for simplicity’s sake.
Companies use project management software for their engineering teams to keep track of what needs to get done, how important it is, and what the current status is on outstanding work. The most popular tracking software for engineering teams is called Jira, made by Atlassian. Upstarts Linear and Shortcut (formerly Clubhouse) are popular too. In Linear, each unit of work is an “issue” and they have associated metadata like status, who created it, how important it is, etc.
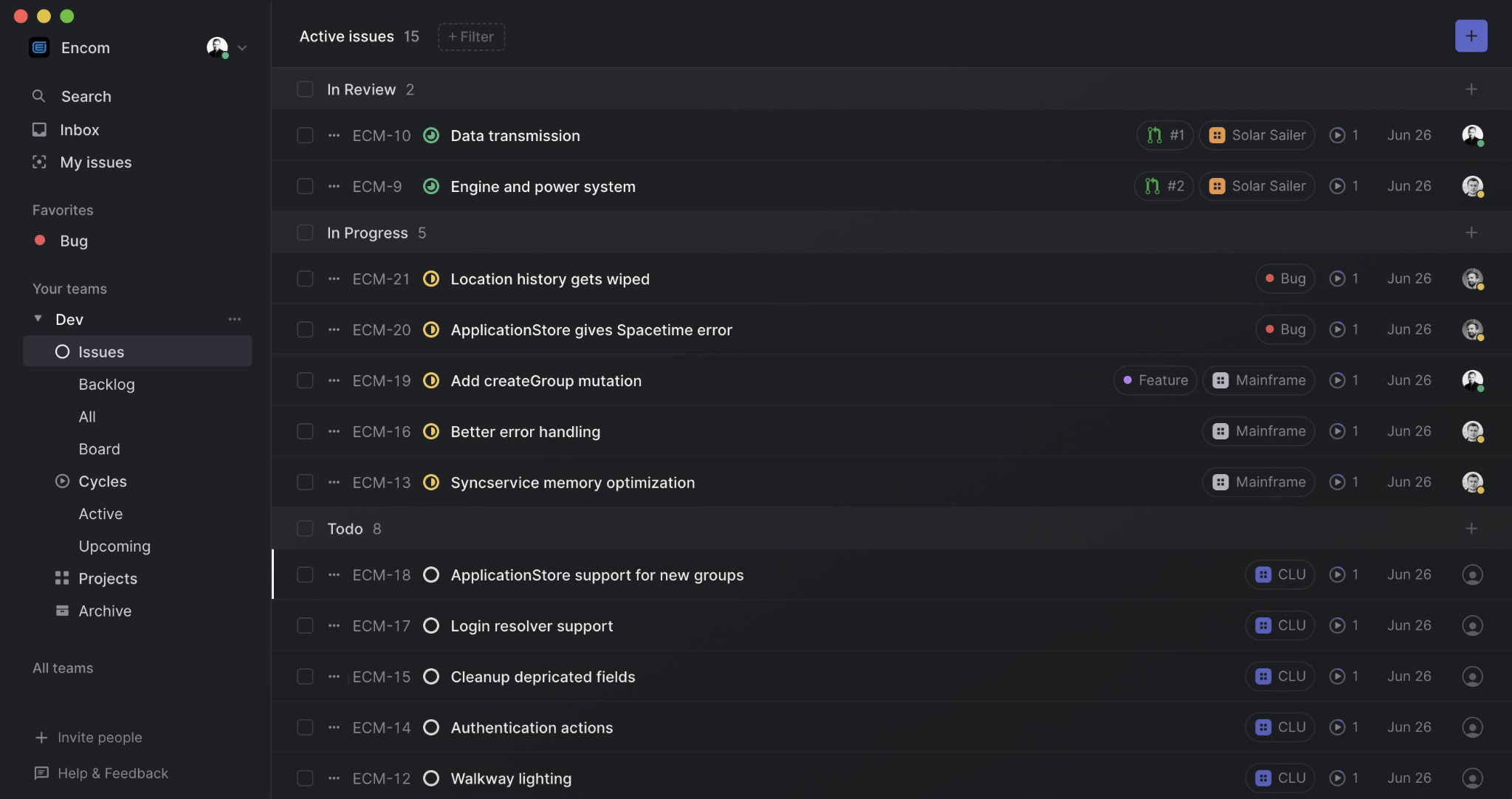
These project management tools also integrate with engineering tools like GitHub so viewers can see new code attached to specific issues. That little green icon at the top for ECM-10 and ECM-9 signals that there’s a Pull Request (more on this later) in GitHub associated with the issue, i.e. an engineer has working code for the work.
Companies prioritize engineering work based on what’s going to be most impactful to the business. That’s easier said than done though; what happens if your sales team is working on a $1M contract that needs a new feature built to close the deal? What happens if you have so much technical debt that some impactful features are unlikely to ever actually work? Anyway, I’m glad I’m not a product manager.
Back to our example, moonlighting as a Substack engineer. Our product team has been working on improving the posts page, where writers can see all of the posts they’ve written and edit them. They’ve identified a problem – once you have a bunch of posts, it’s hard to find the one you want, since it’s just a giant list:
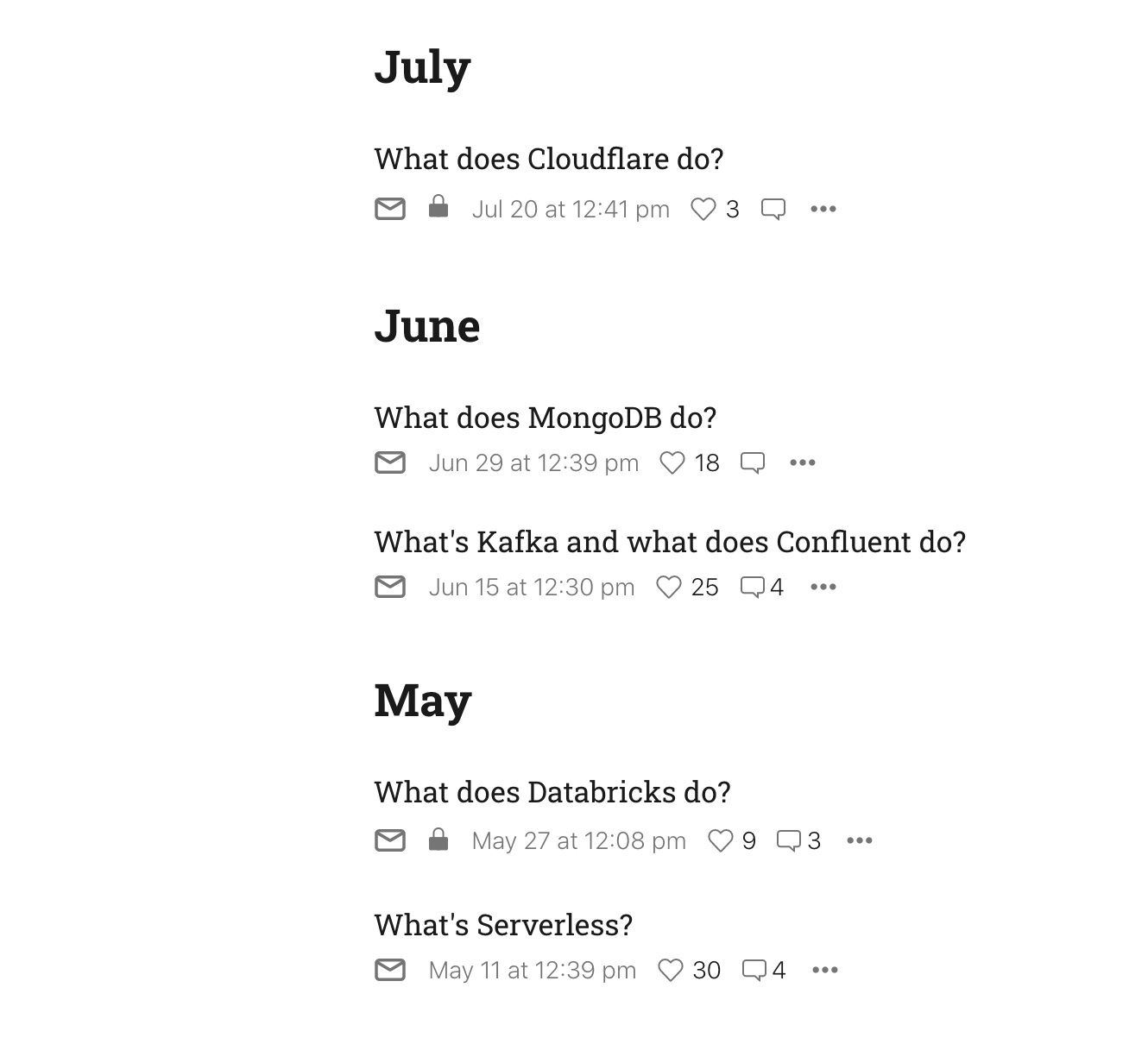
The solution is to add a search bar that lets users (writers) search for whichever post they’re looking for. BTW, Substack, please actually add this.
The first step (aside from planning) is to get the feature working on your laptop.
Build it locally
Once, as an engineer, you’ve decided what to work on and how you’re going to build it, the next step is to build a working version on your local machine.
The local development model
First, let’s understand the model for how this works.
Application code (what users interact with) exists on a set of servers in the cloud
Companies manage all their code via a cloud service like GitHub
Developers maintain a copy of that code on their personal machines
Developers start by building features locally on their laptops, and then uploading to the web
The way that software development works at most companies is a bit confusing – developers maintain a full copy of all application code (frontend and backend) on their laptops. When developing a new feature, you build it locally and get it working on your laptop, and then you worry about getting it into your actual production application.
GitHub works via branches – unique versions of the same set of code – that developers use to manage the code they’re working on. The most up to date code usually sits on a branch named `master`, and that’s the version of code that gets served to users. Sometimes there will also be a `dev` branch that’s more experimental and has some new features on it that haven’t been fully tested.
Getting ready
So to get started, we’ll clone the main Substack code repository to our laptop (if we haven’t yet), and pull the latest changes that other developers have been working on. Then we’ll create a new branch for this search bar work and call it justin/add-search-bar-to-posts-page. That way the code I’m editing is brand new and won’t affect anything existing.
We’ll also need to make sure the app is actually running locally, i.e. our local backend is accepting requests and the frontend is running and showing the pages we need. Dev teams build tooling around this to make life easier for teammates, e.g. scripts that start up the app easily and troubleshoot common issues.
Building the feature
Now, the actual work – building the feature.
For our search bar, we’ll need to add the text input UI element, build some sort of function to filter a user’s posts, and then decide how to render that (highlight text matches?). If the feature is easy, things don’t take too long. When I added search to the Technically website, it took me a few hours, max.
If a feature is larger or more complicated, things can be slower. An important question to ask is does this require backend changes? For our search bar, the answer is generally no – this is a frontend only change (at least for a basic implementation).
🔍 Deeper Look🔍
To play devil’s advocate, if a user has thousands of posts, building search as a frontend filter could end up being too slow. In that case, we’d want to build a new API endpoint for searching posts, use a SQL query (or whatever database you’re using) to filter posts in the database for the search term, and return the results to the frontend. So again, everything depends on your app’s constraints and users.
🔍 Deeper Look🔍
If you do need to change the app backend, that can add a bunch of time to the expected project length. A good example is changing any user information. If we want to add the ability for users to toggle between light and dark mode, we’re going to need to store that data somewhere in our database. If we have a `users` table, we can add a column called dark_mode that’s either true or false and then update it based on what the user chooses.
If you’re using a relational database (like most companies are), teams will apply database migrations whenever they change the backend. A migration is a granular record of any schema changes to your database, like the above column add. They help keep track of how your database has changed over time, and make sure developers are all working with the same version of your schema.
So after a few hours of grinding with some low-fi beats on, we’ve got the search bar working locally on our laptop. The next step is to get it integrated with the rest of the codebase and ready for production.
Get code ready for production
Once our local code is ready to go, we need to integrate the changes with the rest of the codebase. Either after they’re finished, or periodically while developing, developers will push their changes to the cloud – so that the new branch exists on the web – and then open what GitHub calls a pull request. A pull request is basically saying “I want to merge this new code I wrote into the codebase.”
🚨 Confusion Alert 🚨
The “develop locally, push to the cloud” workflow can be a bit confusing at first. You can think of it like saving a document – you want to save every now and then so you don’t lose your work, but not every 2 seconds. Similarly, when I’m working on code locally, when I finish a chunk of work and commit it, I might push the branch to the cloud to make sure it’s backed up there.
🚨 Confusion Alert 🚨
Before you can merge it though, you want to give your fellow engineers a chance to look at the code you’ve written so they can comment on it. Sometimes they’ll have tips for making things more efficient, or questions about why you did something the way you did. GitHub shows the difference between your branch and the branch you built it off of, so engineers can see what you did:
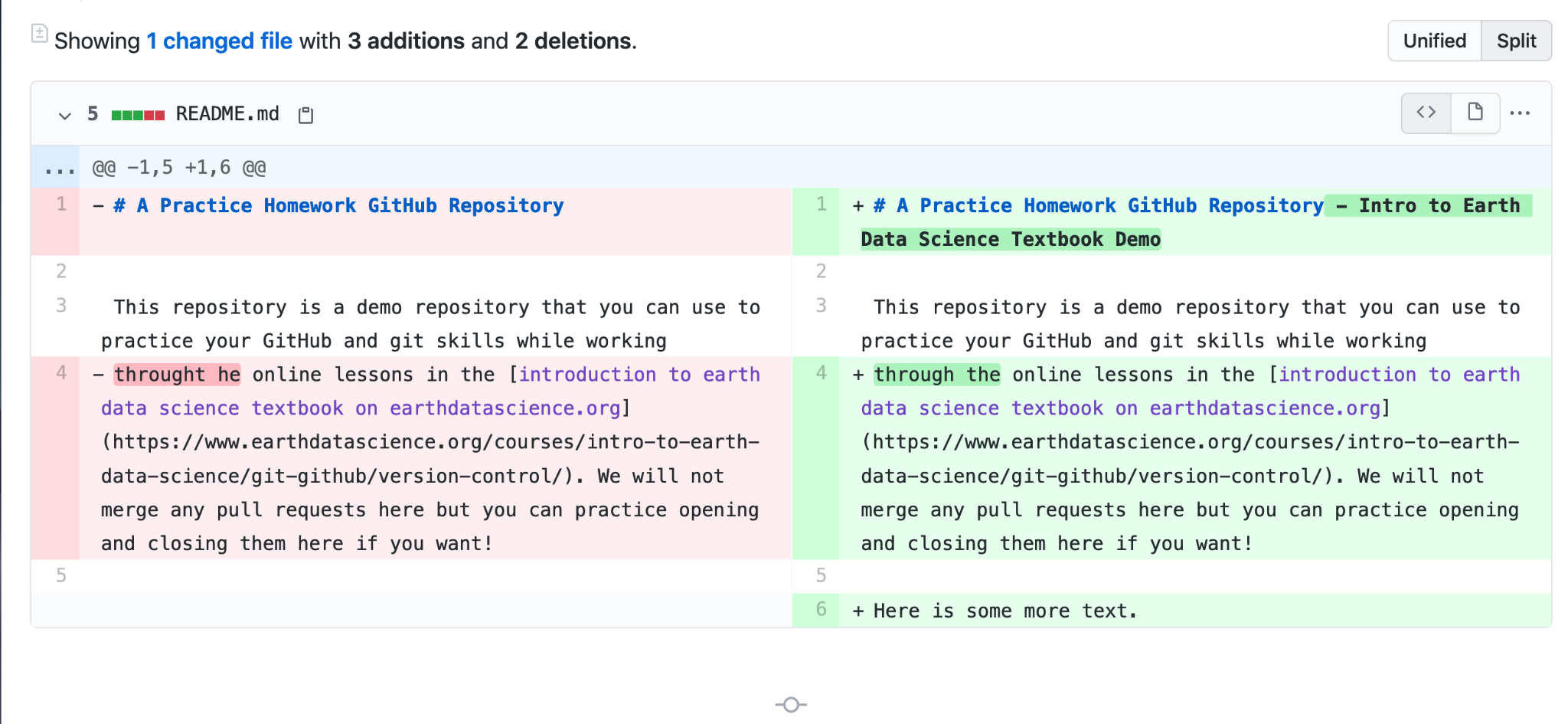
But most importantly, pull requests are a time for you to run that fabled CI, or continuous integration. The biggest risk of merging in new code is that it might break your app for some reason or another that didn’t surface when you were developing it locally. Engineering teams build extensive suites of tests – literally it could be thousands of them – to make sure that all code will work as expected when deployed to your users. Those tests, or checks, can look for things like:
Does code follow proper formatting rules (linting)?
Does running the code lead to any errors?
Does running the code result in what we expect it to?
You can integrate whatever system you’re using for these checks (CircleCI, etc.) with Github so that they run on the code in question on each new pull request:

At some point, when you’re running hundreds or thousands of tests and builds, and your engineering team is opening 20+ new pull requests per day, things can get hairy – tools like MergeQueue sit on top of your Github setup and help you manage your queue of pull requests.
Finally, as part of developing a larger new feature, you’ll be expected to write new tests that verify it’s working as expected. Once your team approves the new code and the tests are in the green, you can merge the new code into production; the final step is building and deploying.
Get code into production
This is where things start to get less standard. Every company deploys their app slightly differently. Everything starts, though, with a branch of code in a version control system. We’re coming off having merged our new branch into the codebase – but what does that actually mean?
Many teams will have that dev branch that we mentioned. This is usually tied to a staging environment – a second version of the app, only accessible by people at the company, that mirrors the production version as closely as possible. You’ll build the new code there first, test that it’s working (again), and then push it out to your users. The difference is that automated tests during CI can only do so much – you still want to manually see how the app looks and test the feature you’ve built. For us, that would mean we go to Substack’s staging environment and type a few words into the new search bar, seeing how it reacts. Ideally, it behaves exactly the same as it did when we built on our laptop, what seems like ages ago.
⛓ Related Concepts ⛓
When using a Platform as a Service like Heroku or DigitalOcean’s App Platform, they allow you to set up automatic deploy triggers. You connect to your GitHub setup, choose a repository and a branch (let’s say master), and then it will redeploy your app with the new code automatically whenever the branch changes.
⛓ Related Concepts ⛓
Once a day, week, or whenever, it’s time to promote what’s on the dev branch up into master and get it deployed in production. This basically involves getting the new code to wherever your app is deployed – Heroku, Kubernetes, whatever – and then rebuilding / redeploying it. That includes starting up containers, applying updates, starting up databases, and things like that. Good engineering teams have this mostly automated (this is the CD part of CI/CD), but will sometimes run manual builds to fix important bugs or for other reasons.
And then the cycle starts all over again! For more about the particular pieces and names of software that developers are using throughout this process, check out the software stack post here.
Wow... there's so much good content here already but this post has got to be one of the best pieces I've read yet. Breaking down the second to last paragraph into a post or a series of posts would also be crazy awesome.
You are teaching me (co-founder of a WealthTech) exactly what I need to know about software development. Thank you!!